This post is based on the ideas and insights of Hans Dockter, Gradle founder and CEO and lead author of the Developer Productivity Engineering Handbook.
In the course of engineering new solutions that improve developer productivity by speeding up builds and tests, Gradle will introduce new concepts and new enabling technologies. Here we will introduce and explore the concepts and technologies associated with performance consistency and performance continuity and the benefits of achieving elevated states of both. Let’s begin by defining performance consistency and contrasting it with performance continuity.
1. Performance Consistency
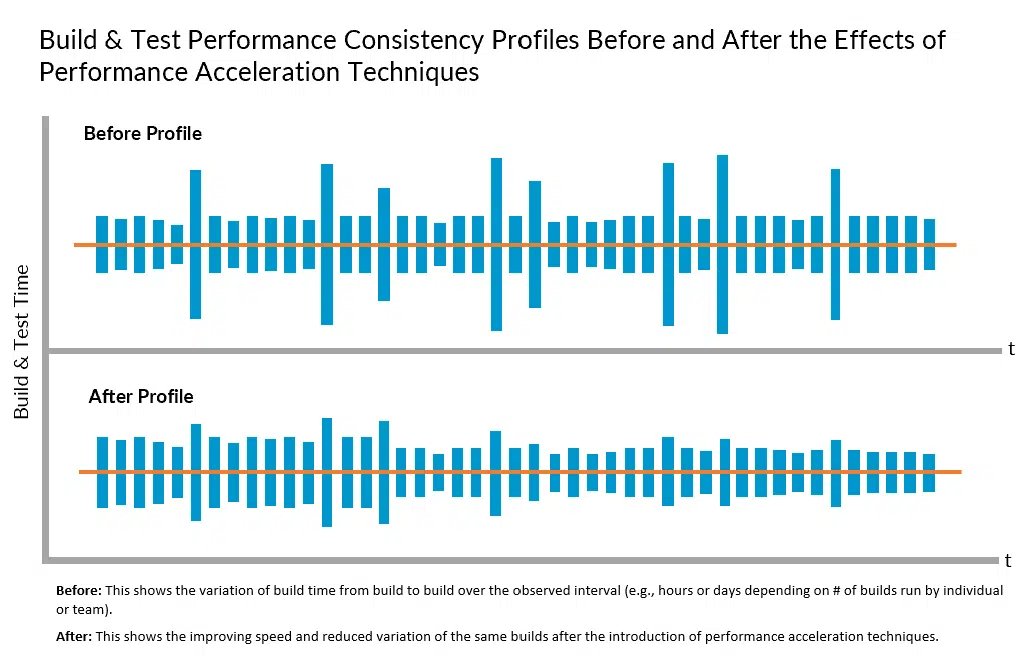
Performance consistency refers to the ability to achieve minimum variation in build and test feedback cycle times at minimum cost regardless of the change that is triggering the build. Performance acceleration technologies, such as build caching, predictive test selection, and test distribution, can be used to improve feedback cycle time consistency, as well as average cycle time.
However, the effectiveness of a single performance acceleration technology may vary depending on the type of change. For example, in the scenario where only build caching is deployed, a build triggered by changes in certain areas of the code base might change the cache key for most of the build actions and result in minimal time savings. Thus, using one acceleration technology may result in a significant reduction in average build time, but a lesser reduction in maximum build time across all changes that have triggered builds.
On the other hand, by using all major acceleration technologies, not only will the average build time be even further minimized, but the maximum build time will not deviate that much from the average. Thus, a key benefit to addressing performance by leveraging multiple performance acceleration approaches is to not only achieve lower average feedback cycle times, but also to increase developer trust and confidence in the toolchain’s ability to deliver that feedback within a consistent time envelope.
Faster average feedback cycle times encourage developers to build earlier and more often because they minimize the impact on developer creative flow and mitigate the productivity impact of preventable context switching. However, this behavior may be somewhat compromised if an average of build and test time has a large variation. This may be the case, for example, if a developer must plan for a build, with an average cycle time of two minutes, to take up to twelve minutes to run. In other words, a developer’s behavior may change for the better if he/she can count on a build taking two minutes rather than having a mindset that builds take up to twelve minutes to run.
In sum, developer willingness to get toolchain feedback early and often, which is one of the foundations of agile development, can be reinforced by achieving a higher level of build and test performance consistency.
2. Performance Continuity
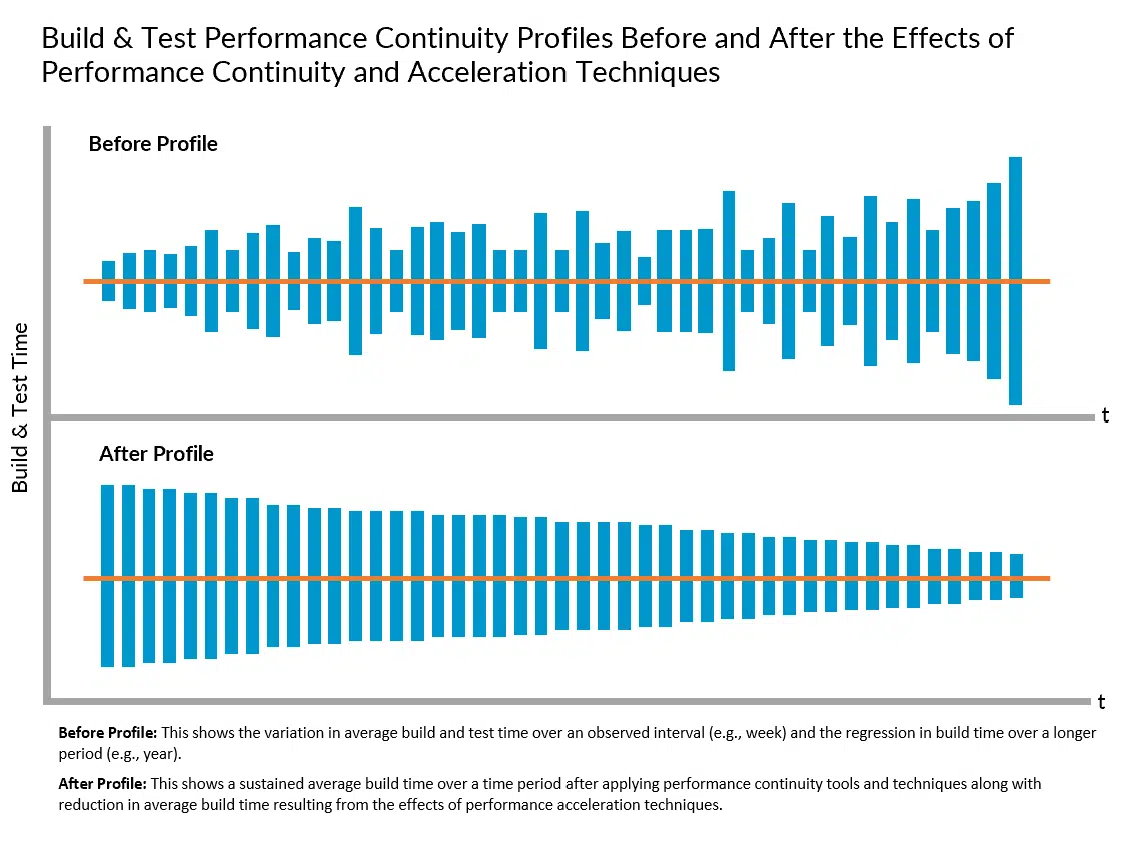
While performance consistency refers to build and test cycle time variation from build to build, performance continuity refers to the ability to sustain improvements in average build and test time over a period of months, as inputs continuously change and the number lines of code, repositories, and dependencies grow. The practice of Performance Continuity Engineering (which can be viewed as a sub-practice of Developer Productivity Engineering) aims to enable observability of significant regressions, or slow regressions in cycle times that may result in an unnoticed and suboptimal “new normal” over a lengthy period of time (e.g., year over year). Proactive steps can then be taken to identify and address the root causes before performance atrophy negatively impacts both the developer and end-user experience.
2.1 Performance Continuity as Part of a Broader Performance Acceleration Strategy
Performance continuity can also be viewed as part of a comprehensive strategy and performance acceleration solution suite to achieve and sustain maximum build and test performance and pursue continuous improvement. For example, build caching can be used to avoid unnecessarily running components of builds and tests whose inputs have not changed. Predictive test selection aims to augment that by running only tests that are likely to provide useful feedback using machine learning. And test distribution is designed to run only the necessary and relevant remaining tests in parallel to minimize build time.
However, a critical mistake is to view these performance acceleration technologies as “fire and forget” solutions. Unmanaged, performance optimization opportunities will be squandered, and performance will regress overtime as the codebase and technology stack grows in size and complexity, leading to potentially negative savings. Performance continuity best practices and tools are designed to ensure that will never happen.
2.2 Develocity Performance Continuity
The Develocity Performance Continuity solution provides a comprehensive set of complementary analytic tools that ensure that product delivery times are not systematically impacted by codebase and toolchain changes, and cycle time improvements continuously and incrementally progress towards the maximum achievable.
For Gradle, Maven, and Bazel build environments, it provides observability of regressions and profiling for performance issues and pathologies that can be used to trigger proactive performance improvement interventions, often before developers even notice and begin to complain.
This has two important outcomes. First, developer productivity stakeholders are so used to relying on tribal knowledge and outdated assumptions about their build environment, they often fail to see or believe what’s at the root cause of their performance issues. The collection of “factual” data may positively change the cultural environment in a way that will increase the success rate of continuous improvement initiatives.
Second, Performance Continuity provides analytic and trend data so that deviations from baselines and actual historical performance norms can be easily observed and dealt with proactively. This avoids the many obvious pitfalls of being incident driven. This data is also used to prove the value of DPE best practices to management and increase the incentive to productivity engineers to take up the challenges since they now have reliable tools to measure their impact.
2.3 Key Develocity Performance Continuity Capabilities
Individually and collectively, detailed build performance data profiling, reports and dashboards can help to qualify decisions about where to invest in further build optimization, where to hunt for potential performance bottlenecks, and where specifically to focus improvement experiments. Develocity provides the following dashboards and profiling tools that deliver this data (definitions/descriptions of each can be found here):
- Performance Dashboard
- Build Timeline Profile
- Build Performance Details Profile
- Configuration Time Profile
- Dependency Resolution Profile
- Build Action Execution Profile
- Build Cache & Test Distribution Profile
- Predictive Test Selection Profile
- Network Activity Profile
- Switches & Infrastructure Profile
- Test Performance (Slow Test Analysis) Profile
Next Steps
Learn more about the Develocity Performance Continuity solution technology by visiting gradle.com/gradle-enterprise-solutions/performance-continuity/.
Here you can also explore the Performance Continuity Engineering Framework. This simple framework demonstrates how the analytic data, insights, and performance profiling information available in Develocity can be used to achieve high levels of performance continuity. It provides a taxonomy of performance continuity problem types and sources you can use to reason about, analyze and address the systemic root causes of common performance bottlenecks and continuity challenges.
For a more in-depth discussion of these topics, please download the Developer Productivity Engineering Handbook, written by Hans Dockter, et al.