Prioritize build reliability
Unreliable builds decrease code quality and are a massive distraction from the developer workflow. Failure Analytics pulls data from every build and test run so you can make build reliability a priority. By identifying where and when failures are occurring, you can invest in the right places, fix issues early before their impact grows, and reduce the time you spend troubleshooting.
Identify the meaningful failures
With Develocity's automatic categorization of verification vs. non-verification failures, you can focus on fixing the code causing “real” failures and better collaborate on eliminating the pesky non-verification failures.

Leverage AI to group common failures
Develocity uses AI to group build and test failures into categories, so you can identify a common root cause and address multiple failures at once, reducing the time you spend troubleshooting.

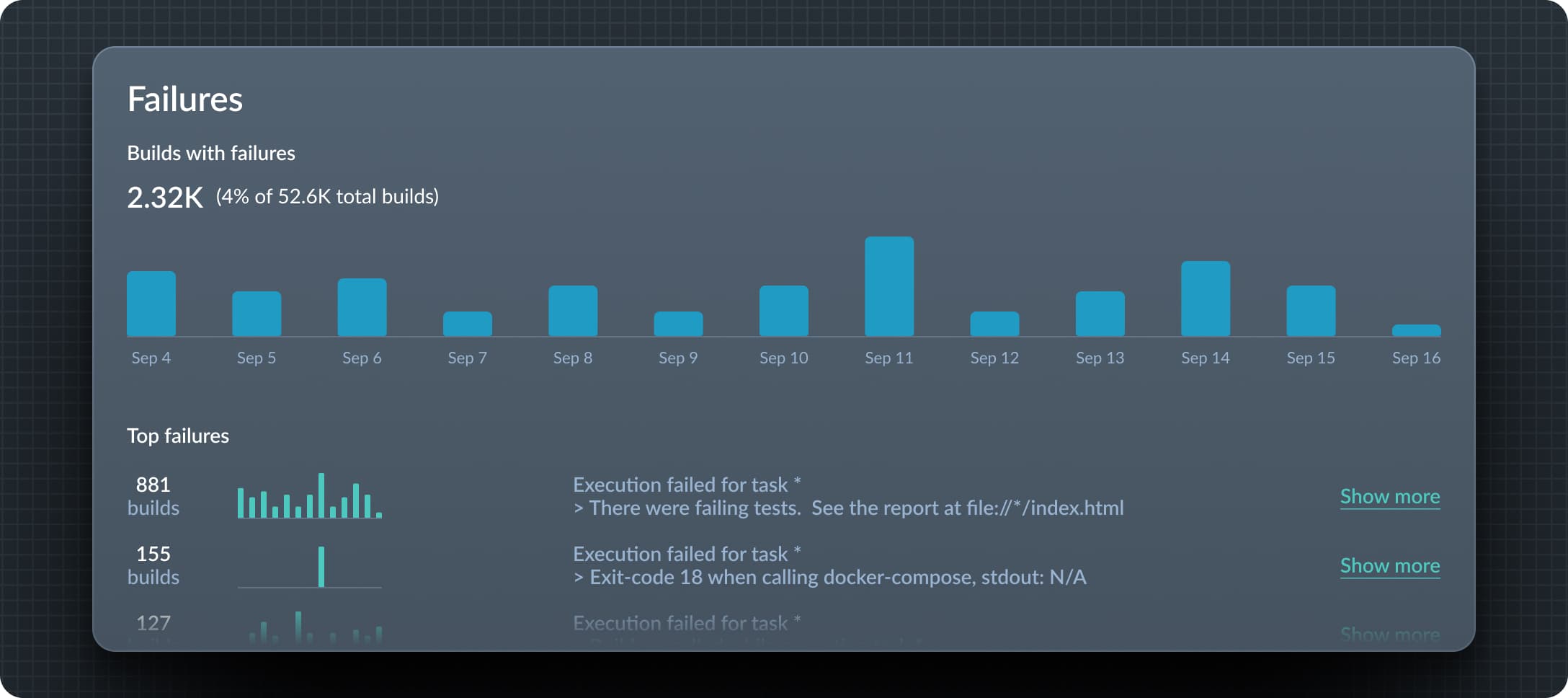
View build failure history
See the failure history across all local and CI builds, common traits among failed runs, and differences when compared to successful runs. You can then measure the impact of failures and see whether it's decreasing over time.
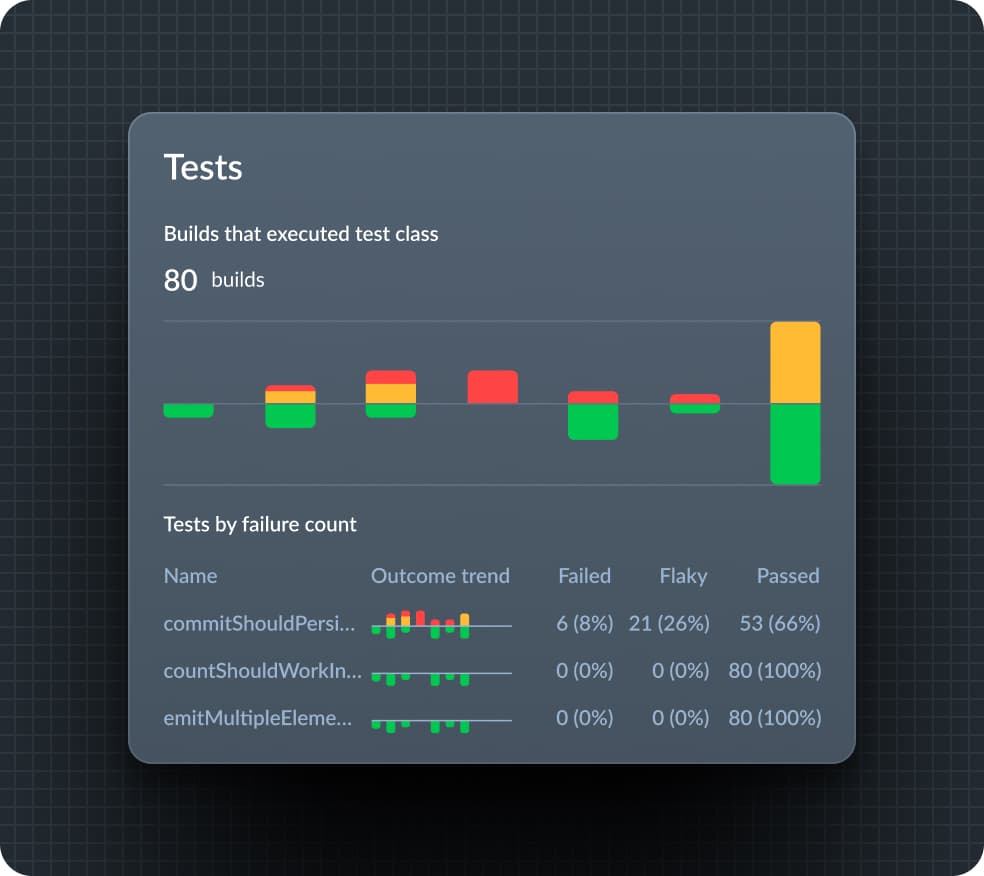
Triage failed tests
Separate the tests telling you something valuable when they fail—for example, that there's a problem in the production code—from flaky tests, so you can address the root cause of each.
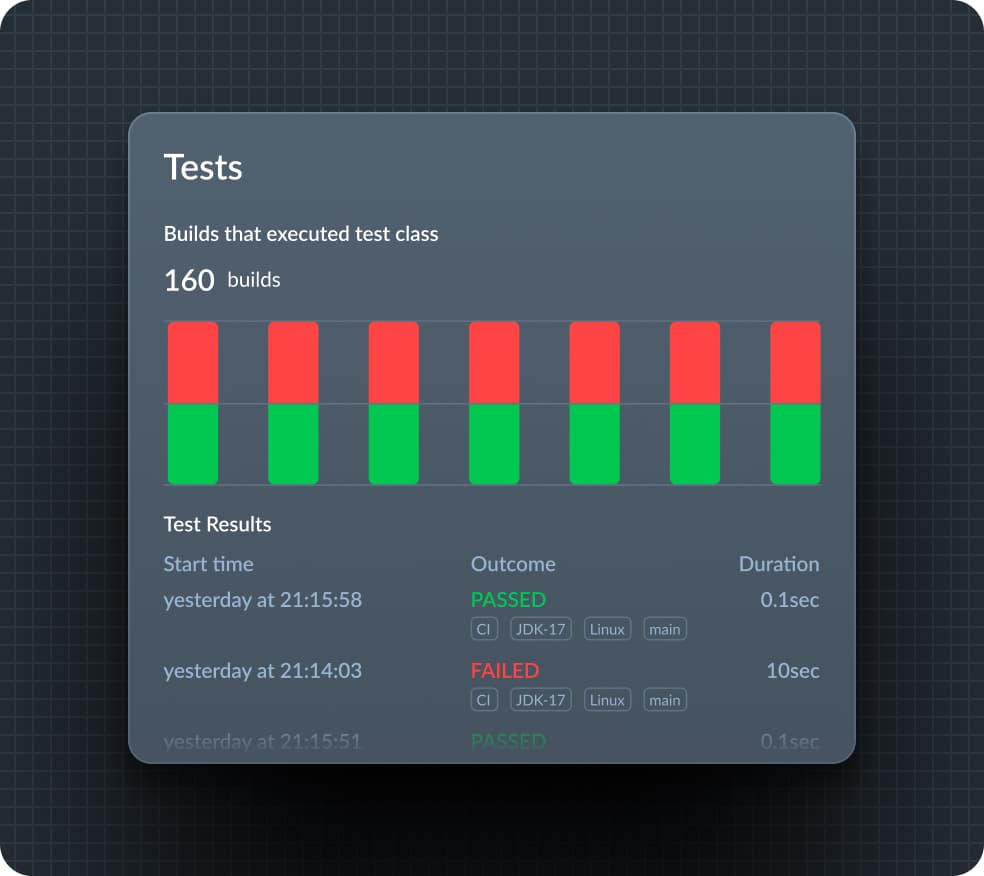
Streamline root cause analysis
View a listing of build environment metadata plus performance characteristics for failed test executions compared to passing ones. See the “before” of when particular tests started to fail to determine root cause.

See how Develocity customer Criteo reduced time-to-resolution for build failures from 30 minutes to 30 seconds.
Get the storyDependency resolution between artifacts is really clear to us. We are better equipped to handle these issues because we don't need to start from scratch—it used to take us up to 30 min to compare dependencies, but now we can just compare the latest build with the last successful build and immediately see which dependencies have changed.