 Flaky tests pose substantial challenges due to their unpredictable and inconsistent nature. Effectively addressing them requires a multi-faceted approach that involves the effective integration of strategy, process and resource alignment, and a deep understanding of flaky test causality. This post will walk you through this approach.
Flaky tests pose substantial challenges due to their unpredictable and inconsistent nature. Effectively addressing them requires a multi-faceted approach that involves the effective integration of strategy, process and resource alignment, and a deep understanding of flaky test causality. This post will walk you through this approach.
Note! This post is part of a three-part series. If you’re not sure it’s worth remediating flaky tests, read Part 1: Seven Reasons You Should Not Ignore Flaky Tests. Read Part 2 to understand the keys to identifying and tracking flaky tests, called 5 Ways to Use Develocity to Identify and Manage Flaky Tests. Now, let’s explore my multi-faceted approach to fixing flaky tests.
1. Deploy best practice strateg/blog/seven-reasons-you-should-not-ignore-flaky-tests/ies
Once you have identified which of your tests are flaky, you can use one of these strategies to mitigate the problems they cause.
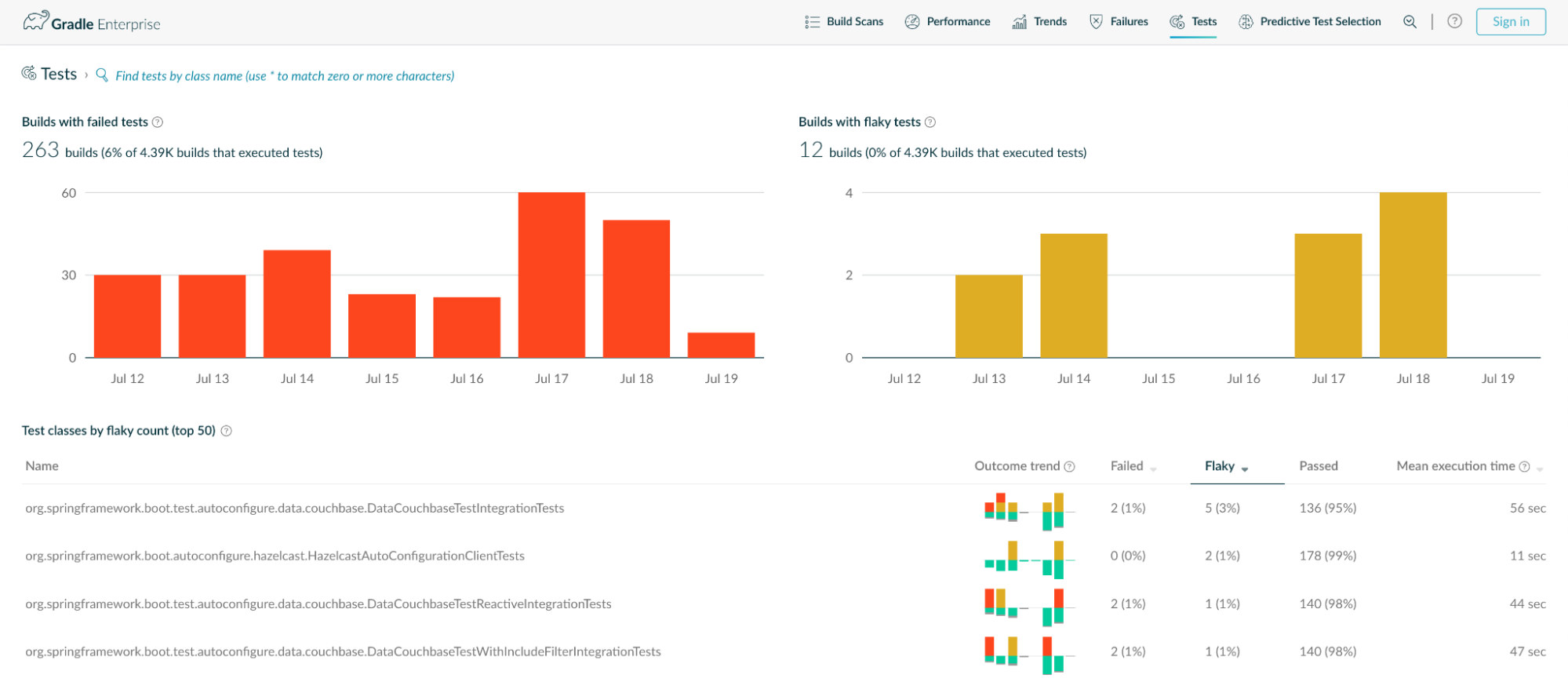
- Quarantine Flaky Tests: Isolate flaky tests to prevent them from disrupting the development process and distracting developers from genuine failures. Once quarantined, these tests can be analyzed separately, freeing developers to focus on legitimate failures.
- Improve Error Reporting: You may need more information in order to find the causes of the test failures. Enhancing your error reporting can significantly aid in handling flaky tests. This can be achieved by adding assertions, checking preconditions, and logging more details about the test environment and state.
- Retry with Care: While retrying can be a useful tool in identifying flaky tests, it’s not a strategy for solving the problem. Retrying until a test passes masks the intermittency and wastes resources in CI and locally.
- Commit to Fixing Flaky Tests: Once you’ve tracked down the flaky tests, and perhaps improved the error reporting and quarantined them from interfering with your team’s productivity, the goal should be to fix the test.
You can also read about how the Gradle Build Tool team handles flaky tests.
2. Align your process & resources
If you don’t want to rely on a few individuals with the discipline and determination to fix your flaky tests, you’ll need to implement some process changes to make sure time is allocated to fixing the problems.
When a developer commits a change that breaks a test, the developer or developers who worked on that change usually start working on fixing that test. This is a well-accepted approach to fixing breaking changes, but it equally applies to tests that start to fail intermittently.
If your application already has a number of flaky tests that aren’t owned by a developer, you may want to schedule regular Flaky Test Days. These dedicated sessions not only aim to decrease the number of flaky tests in your test suite, they also emphasize the importance of addressing test flakiness, and foster a culture of collective responsibility toward improving test reliability.
3. Understand the causes of flaky tests
The causes of test intermittency are varied and nuanced, as discussed by Dave Farley in his video, 5 Reasons Automated Tests Fail, and collated in a research paper on the impact and causes of intermittent tests. Each test may be a unique case, but you may also find that one cause of intermittency affects multiple tests.
Here are some common causes of test intermittency. Note that these categories can overlap, but considering each failure from one of these angles may lead to identifying a fix for the failure.
1. Concurrency, Asynchronous Programming, and Waiting: Asynchronous and concurrent programming pose specific challenges to testing. Tests often have to wait for events to happen before taking the next steps or may run into race conditions in either the test code or production code. There may be environmental factors in these failures too, since tests may time out more frequently if the test environment is under a high load.
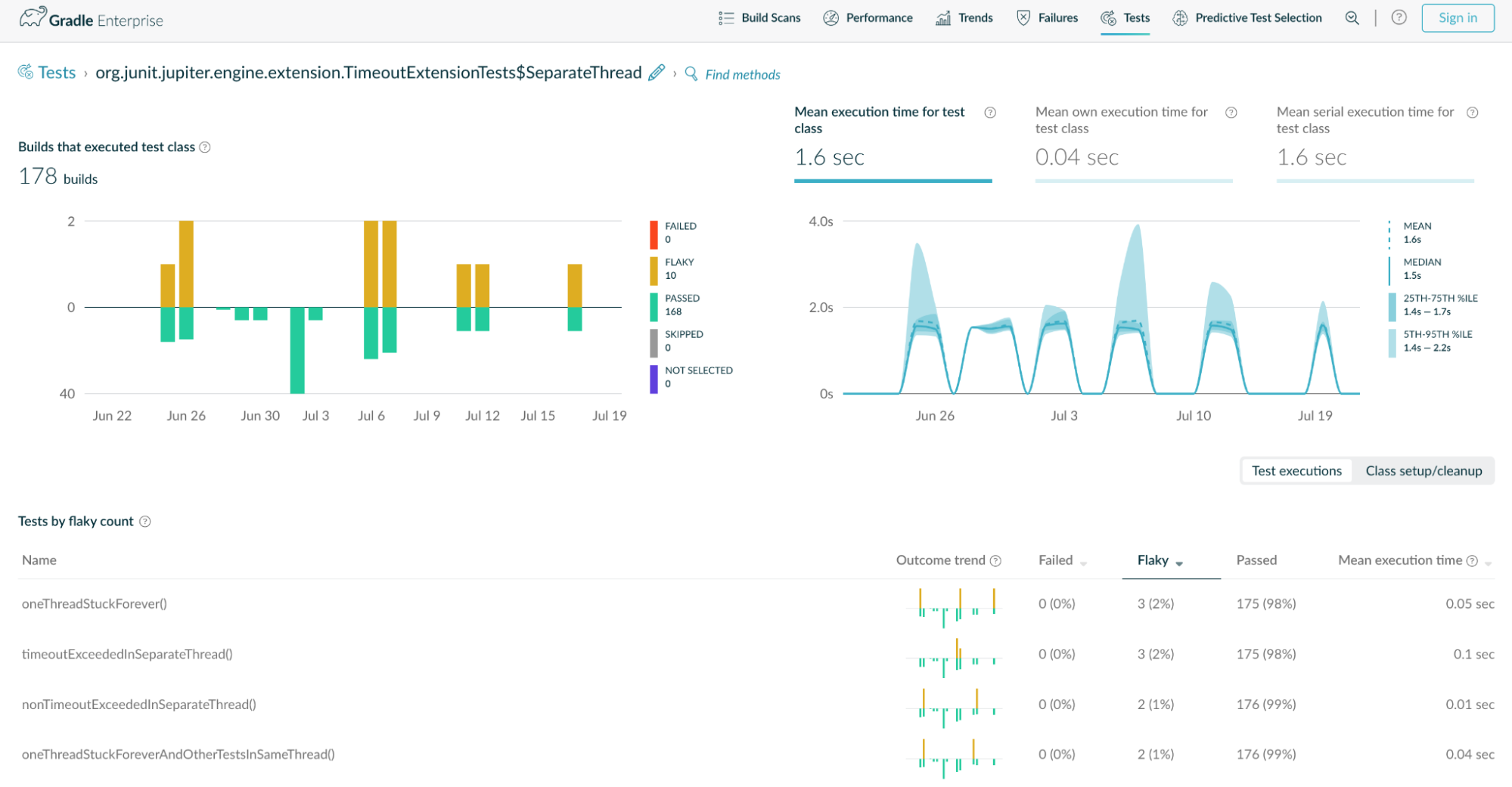
2. Environment, Network, and Resources: Variations in testing environments or network conditions, as well as insufficient compute resources, can result in inconsistent test behavior. Develocity can help you identify some of these issues—it will show details about the environment the tests ran in so you can compare the test results from different environments.
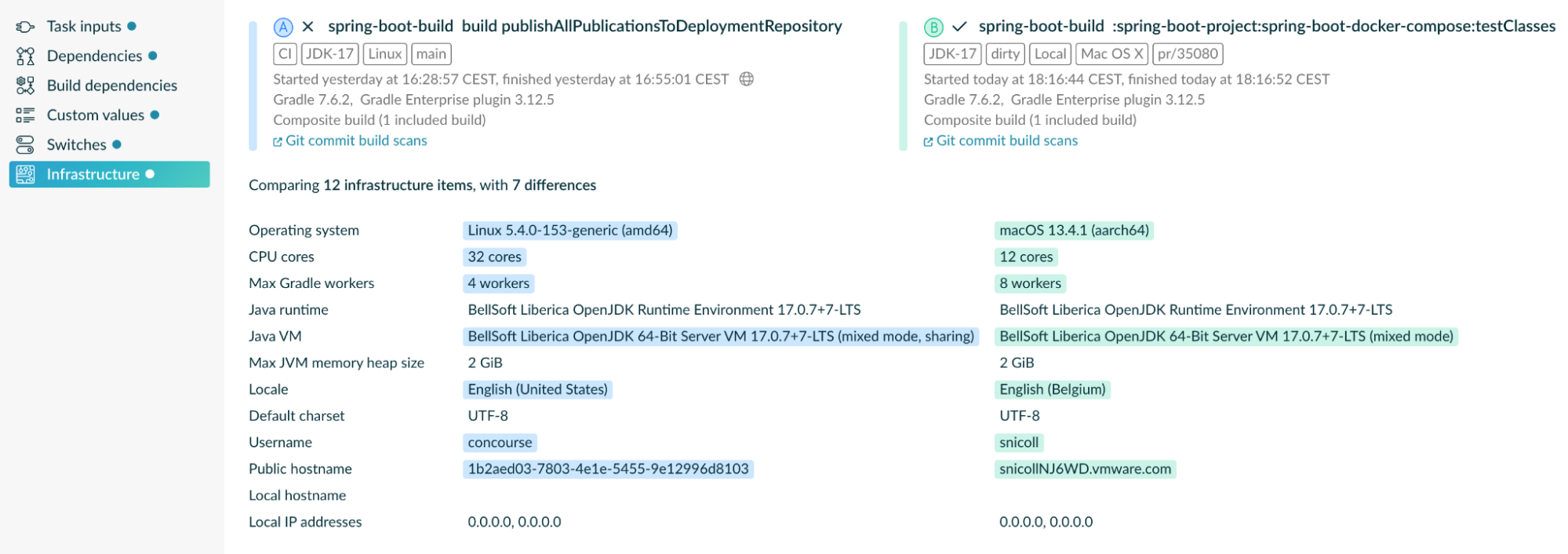
3. Integration Points: Tests depending on external systems or services (integration points) may be flaky due to the unpredictable nature of these dependencies. This includes other services from inside your organisation, as well as third-party libraries and APIs or systems that are external to your organisation. Integration tests against external systems are valuable since they can tell you if your assumptions about the system are correct. However, tests that are designed to run against systems that can change without warning should be kept separate from the main test suite due to their inherently uncertain behaviour. And the main test suite should protect itself from these integration points by mocking and stubbing the expected behaviour.

4. Setup/Teardown and Test Data: Test results can only be predictable if the start state of the test and end state of the test are also predictable. If the tests rely on shared state, shared data, or shared resources (like a database), this can be a contributor to intermittency in the tests. It’s key to make sure the tests run in isolation so they don’t impact the data from other tests. Even when the data is isolated from other tests, you may still run into unpredictable results if your test or production code is something that’s randomly generated, or related to date and time. You may want to inject a custom provider of random values or date/time into your production code so that you can control these values from the test.
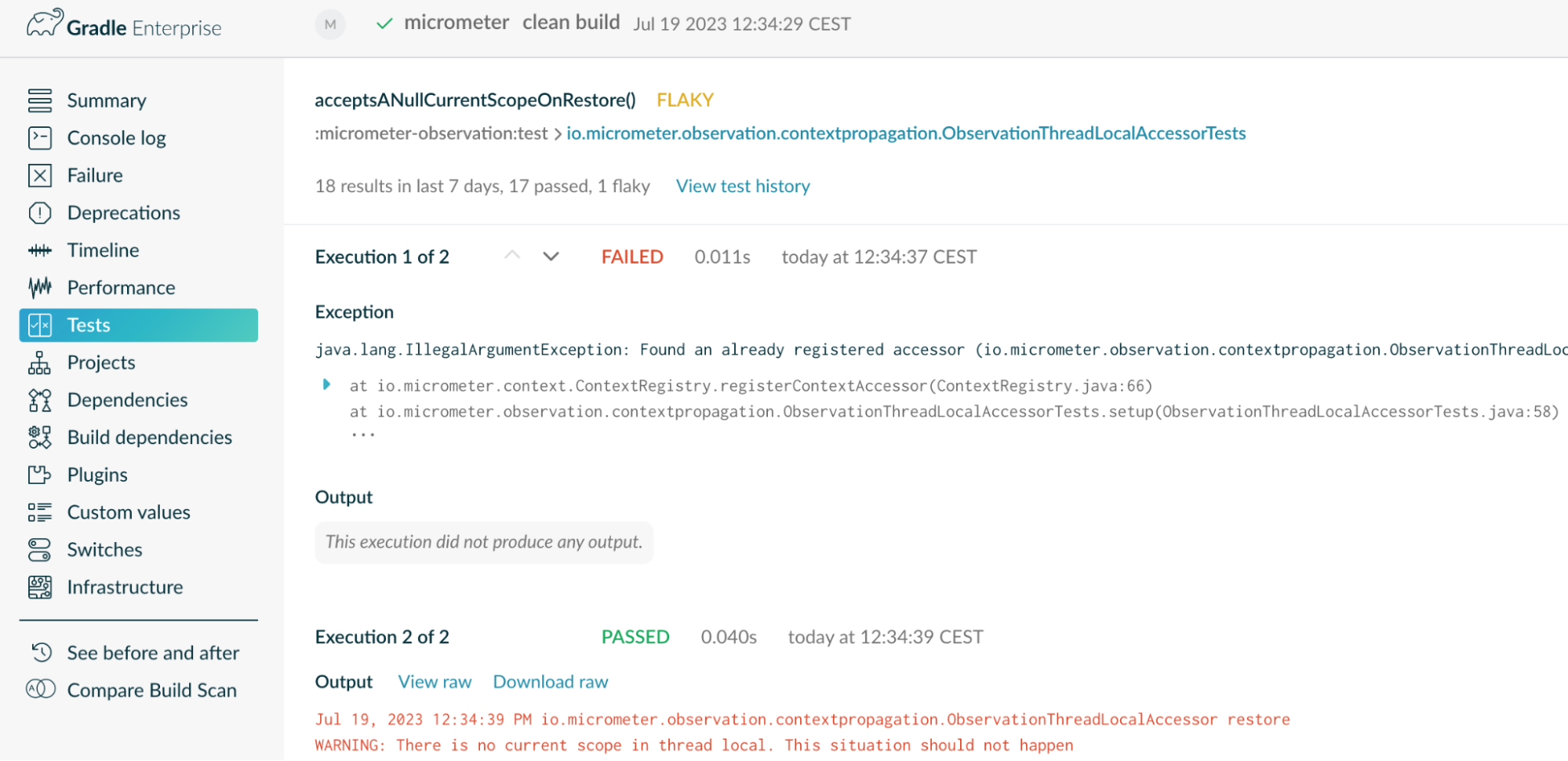
5. System Behavior: While it’s easy to assume it’s some problem with the environment or test data that’s causing an intermittent failure, sometimes the problems lie in the production code of your application. For example, test environments can sometimes trigger genuine race conditions in concurrent code or uncover bugs in third-party libraries. These can sometimes be the most difficult issues to identify but are arguably the most important reason to address flaky tests.
Conclusion & next steps
Efficient management of flaky tests is a combination of strategic actions, process changes, and a deep understanding of root causes, all facilitated by tools like Develocity. By weaving these elements together, your team can effectively navigate the challenges posed by flaky tests, ensuring the delivery of high-quality, reliable software.
Here are two videos I recommend to learn more. The first is about Develocity’s Failure Analytics, which provides Test Failures Analytics and flaky test management capabilities in particular. The second is about Build Failure Analytics, which addresses non-test-related failures like compilation problems.