
HiveMQ started their deployment of Develocity in August 2022 and has seen multiple benefits for its mission-critical testing process. We caught up with Silvio Giebl (left), senior software engineer on the Platform Team, and Georg Held (right), director of product development, to get the low down on their experience and results to date.
Describe what HiveMQ is and tell us about your primary business drivers
Our vision at HiveMQ is to provide the most trusted MQTT platform, a central nervous system to help businesses connect and manage their IoT (Internet of Things) and IIoT (Industrial Internet of Things) devices and data. Since messaging infrastructure is a critical part of our customers’ business, the engineering teams at HiveMQ must ensure exceptional reliability, scalability, and availability for our products.
To continuously meet these expectations, extensive testing is an indispensable part of our software delivery process. All changes are required to pass tests with a sequential duration of around 10 hours. We believe that maintaining exceptional quality and a great end-user experience demands not only this amount of testing but also the ability to fix bugs and add new features rapidly.
What developer productivity challenges or pains have you experienced that you hoped to address with Develocity?
High developer velocity depends on achieving a high level of developer productivity which, in turn, requires fast feedback cycles. At first glance, this seems to preclude the amount of testing that’s required to uphold our product’s quality standards. Distributing tests is a necessity.
Before using Develocity, we split our tests into subsets with other tooling (e.g. Jenkins plugins); however, this approach didn’t scale well with higher parallelism and the non-uniform duration of the different test subsets. Additionally, the test splitting only worked on our CI workers and not on our local developer machines.
With more and more tests, test flakiness increasingly becomes a problem. When dealing with a large amount of tests, even a very small percentage of unpredictably failing tests can result in all builds suffering from at least one flaky test.
Reducing test flakiness is necessary; but it’s almost impossible to completely avoid it, especially with integration and system testing. It hurts developer productivity if developers need to investigate whether a failing test is caused by their changes or their toolchain. Also, there’s the risk of wrongly classifying a test as flaky, which can obscure the real test failures and in turn lead to developers increasingly ignoring some tests. As flaky tests only fail sporadically, it’s often not possible to assess if a test is flaky without historical build and test data.
Besides the number of tests and test flakiness, another challenge was to ensure that bootstrapping new products is easy and does not hurt developer productivity for existing products. The HiveMQ platform consists of multiple parts, and the number of HiveMQ Enterprise Extensions (used to integrate HiveMQ with other systems) will continue to increase over time. More offerings mean more Gradle projects. So the quality of the Gradle plugins and build scripts will become even more important over time.
Describe your overall development environment so we can have some context for understanding your Develocity deployment?
There are 25 engineers embedded in cross-functional product teams working on HiveMQ products. Two of them are in the platform team in charge of build tooling, among other responsibilities.
As a platform technology, HiveMQ products are tightly integrated. To reduce cognitive load, every product lives in its own repository. Additionally, some of our projects are open source, which makes it complicated to operate a monorepo. Fortunately, Gradle’s composite builds provide a perfect solution to our requirements.
The `hivemq` project is an umbrella project that integrates our core HiveMQ Broker product with our 11 HiveMQ Enterprise Extensions and 6 SDKs. Additionally, we have the HiveMQ Swarm load testing product with an SDK, 13 open source HiveMQ extensions, and other open-source products such as the MQTT CLI and the HiveMQ MQTT Client to name a few.
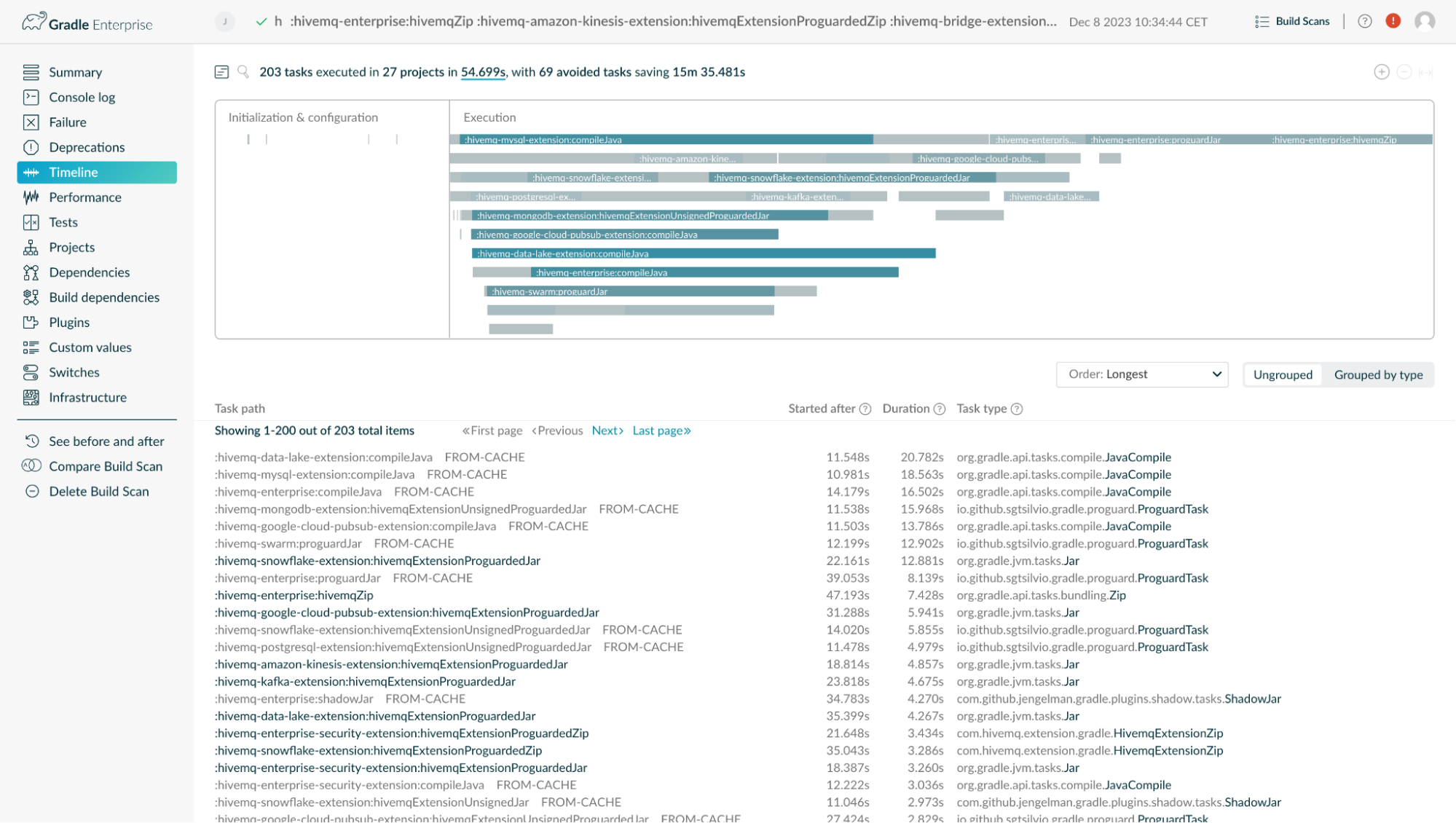
Build Scan® showing parallel task execution of multiple projects
Virtually all of our products run on the JVM and are written in Java. All build scripts and Gradle plugins (e.g., https://github.com/hivemq/hivemq-extension-gradle-plugin) are written in Kotlin. The Kotlin DSL greatly simplifies the maintenance of build scripts.
The `hivemq` project averages 3,000 Gradle invocations on CI per week. Each week, 170 of these run the aforementioned tests with a sequential duration of around 10 hours. Fortunately, the Develocity Build Cache reduces the number of tests that are actually executed, since any unchanged test tasks coming from the cache are not executed.
Describe your test environment—and offer advice for teams operating in a similar environment.
As mentioned previously, running a lot of tests requires distributing test execution. This also means that CI systems need to consist of multiple worker machines. For cost and performance reasons, we don’t use on-demand cloud machines but instead have a fixed set of servers that host virtual machines. Each virtual machine runs a core CI service, such as Develocity and Jenkins or a worker node. Currently, we have 59 Jenkins workers and 59 Develocity Test Distribution agents, each with 4 CPU cores and 16GB RAM.
Test duration is dominated by the parallelization factor, but for overall build performance, it’s also important to avoid unnecessary overhead. While our builds are fully self-contained and operate on clean workspaces (which is required because a build may run on different workers), our workers aren’t ephemeral.
We keep Gradle daemons running and don’t delete local Gradle dependency caches. The more local, the lower the overhead. Fortunately, Gradle daemons and caches are self-cleaning. If something is missing in the local caches, it falls back to shared services before reaching out to, for example, Maven repository caches and Docker image repository caches. The Gradle build cache isn’t kept locally and we utilize the Develocity Remote Build Cache.
Our recommendation for other development teams is to not blindly follow advice suggesting that you do everything in a fully ephemeral setup. For example, removing and reprovisioning the whole CI worker makes it very hard to keep local Gradle caches and impossible to keep Gradle daemons running. This can negatively impact developer productivity if it increases build duration and feedback cycle time.
What’s been your experience with Develocity Test Distribution and how would you describe the business results?
Once all test inputs are properly defined, you just need to enable Develocity Test Distribution and it works. Being forced to properly declare all test inputs increases test reliability and removes concerns about the caching of test results. It’s somewhat similar to migrating build scripts from the Groovy to the Kotlin DSL: if you have some legacy parts of the build, then you need to invest more time for cleanup. But the rewards are very high and efforts pay off quickly.
In our code bases, Test Distribution worked out of the box for unit and most integration tests. Additionally, we have a lot of integration/system tests that use Docker to start our own and third-party applications. These types of tests are more challenging because it’s hard to declare the container images as test inputs.
This isn’t caused by Gradle Build Tool or Develocity Test Distribution, but rather by the Docker tooling. Fortunately, the flexibility of Gradle allows us to close the tooling gap by writing our own plugin. The “Gradle OCI (Open Container Initiative) plugin” is open source (https://github.com/SgtSilvio/gradle-oci) and allows the use of container images as dependencies and, in turn, as test inputs (among other capabilities such as the ability to build OCI compliant images). Gradle is really the only build tool that allows you to represent any build topic.
Putting all these implementation benefits of Develocity Test Distribution and Gradle Build Tool itself aside, Test Distribution really decreased our feedback cycles. Our previous implementation of splitting tests had some scalability issues as well as unbalanced partition durations, so that the parallelization factor maxed out at around 16 tests, resulting in a test time of 30-40 min.
As Test Distribution has less overhead, it allows us to increase the distribution factor. Currently, we’re at 42 parallel tests (but more would be possible) resulting in a feedback time of 10-15 min (a decrease of around 3X). This is important because leadership doesn’t want to compromise on test quality or developer productivity.
What other Develocity features is your team using and what benefits have you seen?
We use Build Scan® to monitor changes in builds over a longer time window. Build Scan allows us to keep a history of builds and their tests which allows for flakiness analysis. Also, the option to search through the dependencies of all included builds is another great feature.
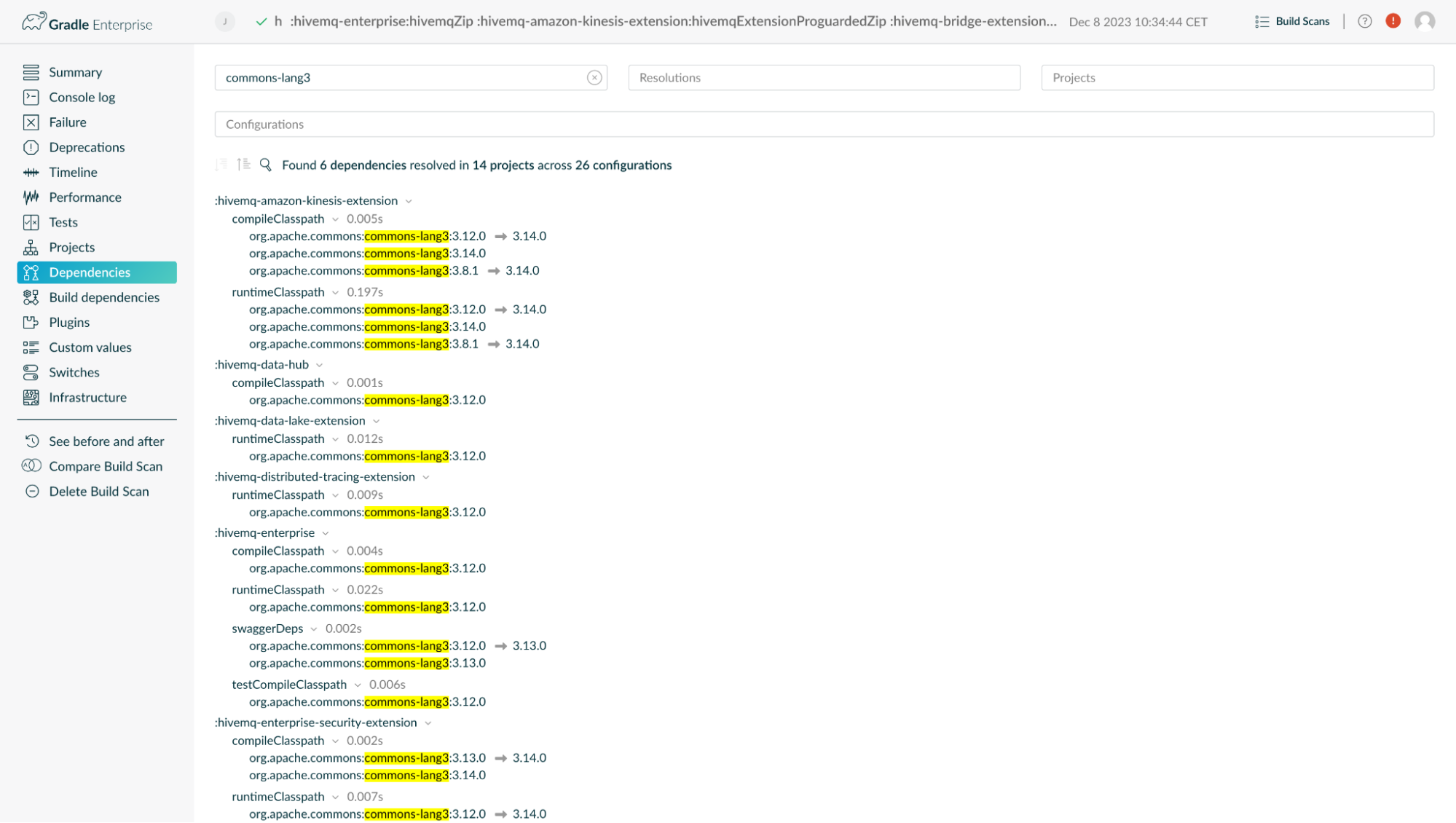
Searching through the dependencies of all included builds using Develocity Build Scan
We use the local Build Cache on developer machines and the Remote Build Cache for CI, as well as on developer machines. The Remote Build Cache is especially useful when you have a large number of CI worker machines.
Finally, we leverage Develocity Failure Analytics and Performance Dashboards. We use the test analytics page for flaky test analytics. Specifically, we use it to prioritize which tests to fix next based on the level of flakiness and scope of impact. Analyzing the trend of test flakiness can also reveal very rare race conditions if there’s an unexpected spike in flakiness compared to the baseline. We experienced an incident where a race condition was detected by an increase in flaky tests, and the fix was validated by an immediate decrease.
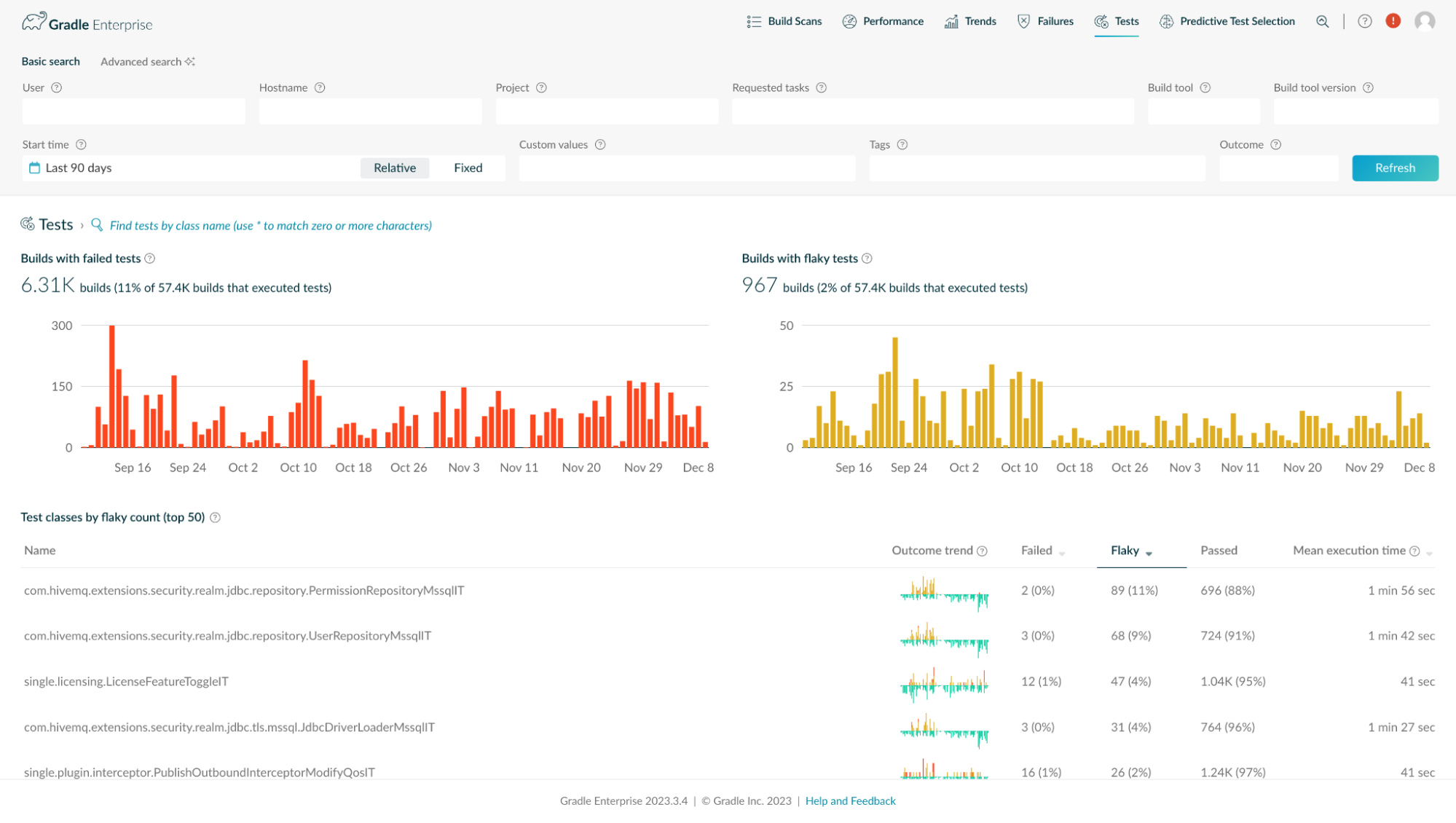
Historical test flakiness data
What impact if any do you think Develocity has had on your developer experience?
Develocity is very valuable for our platform team as it helps to maintain builds and provide a good developer experience, even though it’s a small team. Additionally, other engineers that take care of test flakiness value Build Scan history and test data.
Most other engineers don’t think explicitly about Develocity, but only indirectly experience the benefits of faster builds via the Remote Build Cache and Test Distribution—and that’s a good thing. The results of good developer productivity engineering should seamlessly blend into developers’ work. Mostly, people only notice developer productivity engineering when it’s absent or when there are hiccups.
What are your next steps with respect to Develocity and your Developer Productivity Engineering efforts?
We haven’t yet fully rolled out our own “Gradle OCI plugin”, but the plan is to apply it for all projects that build or use container images. This allows all projects to take full advantage of Develocity Test Distribution right out of the box.
Also, while we already use Develocity effectively to analyze test flakiness, there’s much more we can do to fully leverage all of the available data and act on it more consistently.
Any parting words of advice?
We recommend that all engineering teams should invest in Developer Productivity Engineering. In particular, Develocity can help improve your developer experience.
Apart from Develocity, we also want to emphasize that the Gradle Build Tool has been key to improving our developer experience. It’s not just a great build system for compiling Java code or Android apps, but a reliable general-purpose build automation technology.