
 Observe
Observe Accelerate
Accelerate Troubleshoot
Troubleshoot


In previous blog posts, we’ve unveiled Develocity Test Distribution for both Gradle builds as well as Maven builds. We saw that tests can be sped up significantly by distributing them to remote agents.
In this blog post, we want to explore how to automatically scale the number of remote agents based on current demand, and understand the impact this can have on build execution speed. For this, we’re using a synthetic project consisting of 1000 tests, where each test waits randomly between 0.5 and 1.5 seconds. This simulates unit tests where execution times can vary due to current machine load etc. The serial test execution time of this project is 16m 40s, assuming our average waiting time is 1 second. To support auto scaling we will use Amazon EKS as the compute platform and have a maximum number of 25 remote agents at our disposal to speed up test execution.
With auto scaling disabled and all 25 remote agents immediately available to execute tests, the execution speed is reduced significantly for our synthetic project:
Run 1
(all 25 agents connected, build scan)

Since all remote agents were ready, they could be utilized immediately by the test task. While the overall serial test execution time was 16m 40s, the test task finished after about 48s, resulting in a speedup factor of 21. This factor is not far away from the theoretical maximum speedup factor of 25, even though test executions are unevenly distributed. We can achieve this by distributing tests to remote agents via a fine grained scheduling strategy.
While such a speedup greatly increases developer productivity by reducing feedback time, it also comes with additional infrastructure costs. This can be mitigated by creating remote agents on demand.
Introducing Auto Scaling
Ideally, remote agents are only running when developers actually need them. The new auto scaling feature introduced in Develocity 2021.2 can do just that.
The basic idea is that remote agents are deployed on a platform such as Kubernetes. An auto scaler constantly monitors demand for remote agents by polling a status endpoint in Develocity, and adjusts the number of replicas accordingly.
You can define multiple groups of remote agents, where each group can be scaled independently. In Develocity a group of remote agents is represented by an agent pool, whereas in Kubernetes they are described by a deployment.
Agent Pool
First, we need a new agent pool:
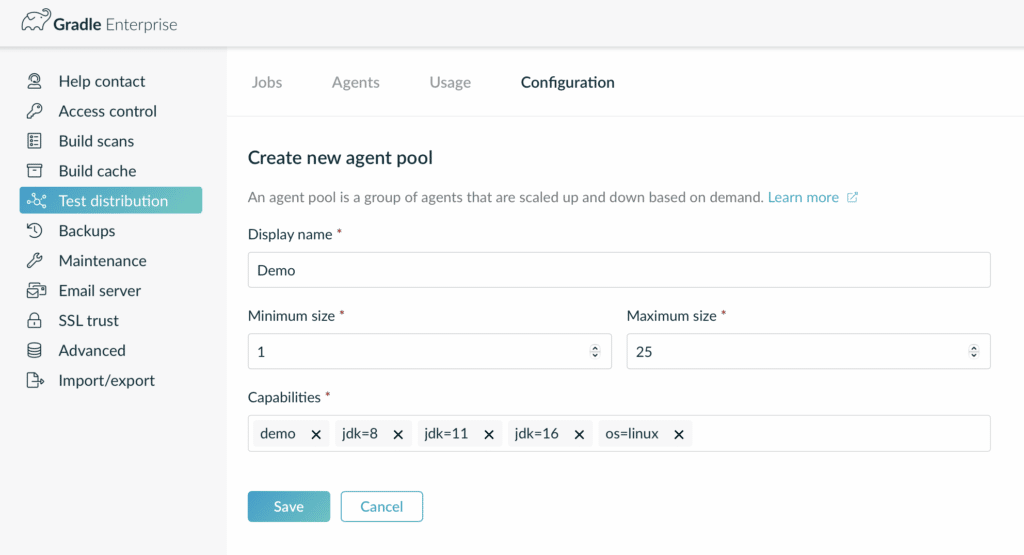
An agent pool has a name, capabilities, and defines a minimum and a maximum size. The minimum size specifies the least number of agents that should always be available at any given time. The maximum size makes sure that the number of agents doesn’t increase without limits.
Next, we have to configure our Kubernetes cluster and connect it with the pool we’ve created before. We can configure our remote agents as a deployment and then configure an auto scaler for this deployment, which calls the pool’s status endpoint in Develocity at regular intervals, adapting the number of desired replicas in the deployment.
With everything set up, let’s run the build again:
Run 2
(start with 1 connected agent, no EC2 instances running, build scan)

The duration for the whole test task took 3m 22s. This is much better than the overall serial test execution of 16m 40s, but it’s clearly longer than the 48s we observed in the initial Run 1. Compared to the first run, we started with just a single connected agent. Kubernetes started scaling up agents as soon as the pool’s metrics indicated it desires more agents.
The usage chart of the pool shows the following:

The number of desired agents immediately jumps to 25 as soon as the build has started (dark blue line). Agents start to connect to Develocity with a delay of about 2 minutes (light blue line). The reason for this delay is that Kubernetes first has to start new nodes in the cluster on which agents can then be started. The time to do this depends on the compute platform and is about 2 minutes in our case.
With this setup, the very first build in the morning will typically be slower, as it has to wait for agents to connect to Develocity.
Since Test Distribution supports both Gradle and Maven builds, let’s run the project as a Maven build this time.
Run 3
(25 agents still connected, build scan)

As you can see, this build is much faster than the previous Run 2. A look at the agent usage chart shows us why this is the case:
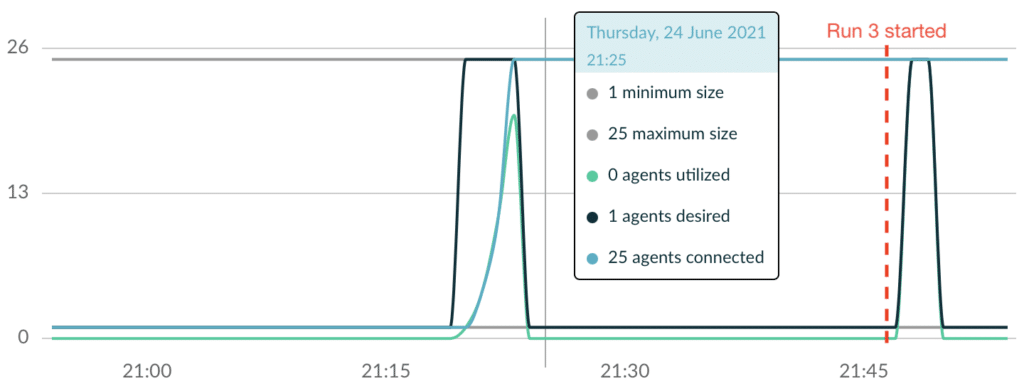
Since all 25 agents were still connected to Develocity, they could immediately join the new Maven build and work on executing tests.
Let’s assume that the next build starts a few minutes after the agents have disconnected from Develocity, because there was no demand:
Run 4
(all but one agent disconnected, builds starts a few minutes afterwards, build scan)

This time the build used 1m 34s to execute all tests. While this is slower than Run 1 (48s) or Run 3 (49s) where all 25 agents were already connected, it was still clearly faster than Run 2 (3m 22s), where only 1 agent was connected.
Why is this the case? Let’s have another look at the usage chart:
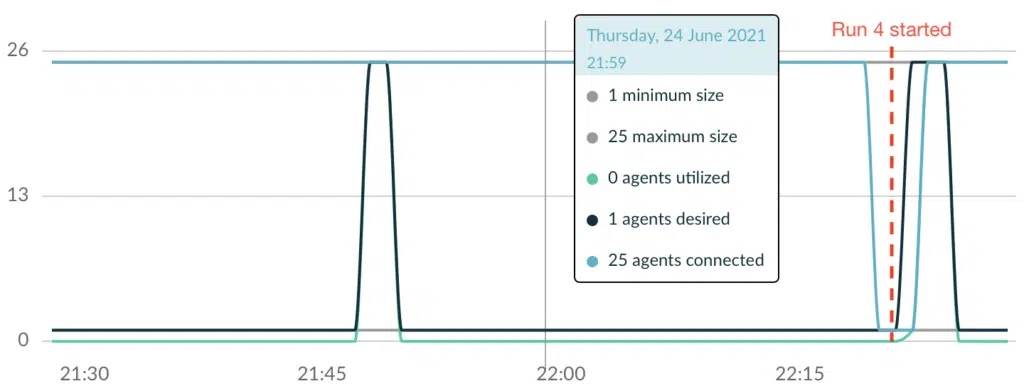
As you can see, additional agents connected to Develocity almost immediately when the build started (light blue line). The reason for this is that Kubernetes did not immediately stop the EC2 instances when agents disconnected from Develocity. Instead, it stops them gradually over time based on the overall usage of the nodes. In our case, all the nodes were still available, so Kubernetes started agents on them in a timely manner.
Conclusion
The auto scaling feature of Test Distribution reduces infrastructure costs incurred by running remote agents, while keeping the advantage of reduced feedback times for developers. Develocity offers easy integration in a Kubernetes environment, and works well with other platforms for managing containerized workloads.
Auto scaling for Test Distribution is available now. If you’d like to try it, or other Develocity features such as the Build Cache or Build Scans, talk to us about a free trial where we’ll help you evaluate and quantify the benefits of Develocity for your organization.